
.svg)

Error Budgets Defined (And How to Make One)

Wondering what error budgets (EBs) are and how they are useful? We explain what they are, how they are defined, and how they can help your team.
What is an Error Budget?
An error budget is the amount of acceptable unreliability a service can have before customer happiness is impacted. If a service is well within its budget, the developers can take more risks in their releases. If not, developers need to make safer choices.
In complex systems, failures are inevitable, error budgets normalize failure as a part of the development process. It also bridges the gap between the development and operations teams by reducing organizational silos and sharing ownership of reliability targets.
Site Reliability Engineering (SRE)
To understand error budgets, you need to understand SRE. Site Reliability Engineering (SRE) is a set of practices employed by tech giants such as Google, Netflix, and LinkedIn to continuously improve the reliability of their services.
SRE practices monitoring, alerting, incident response, postmortem, testing, capacity planning, and development to make a service reliable. The following illustration lists SRE practices that make a service reliable, from basic (at the bottom of the pyramid) to advanced:

SRE Team and The Error Budget
The SRE team comprises software engineers who build software to improve the reliability of their systems. These software engineers are dedicated to improving the reliability of software in production. Some examples of manual work that SRE teams do outside of building software are fixing bugs, responding to incidents, and working on-call. SRE teams work with development teams to set EBs and EB policies.
The error budget burndown provides solid data to the development and SRE teams on how to set release velocity. For example, suppose the EB is 2 hours of downtime in a 28-day period, and two incidents have caused over 1.5 hours of downtime in the first 5 days already. The remaining budget of 30 minutes of downtime determines whether the development team should slow down and spend more time on testing and improving reliability.
What is The Purpose of An Error Budget?
All tech companies share the same goal: innovation. They aim to be better than tomorrow, keep growing at a constant pace and make the world a better place.
When you constantly change and improve the existing product, you will come across or even trigger system failures. With complex systems, pursuing perfection is fruitless. Failure is inevitable at some point, and the best you can do is be prepared for it.
To make mistakes is human, and the purpose of an error budget is to make mistakes without getting caught by your customers!
They help companies make a data-driven decision on how to balance between new features and reliability.
SLI, SLO, and SLA
The notion of SRE revolves around the idea that metrics should be tied to business objectives. Three primary tools are utilized in SRE planning and work: SLIs, SLOs, and SLAs. Without them, you cannot measure your system’s reliability, availability, and usefulness.
SLO (Service Level Objective)
SLO is an agreed-upon objective about how reliable a service should be. It’s the minimum reliability you need to keep your customers happy. In SRE terms, SLO is the numerical target value for system availability.
SLA (Service Level Agreement)
SLA is a formal agreement between customer and service provider that covers the repercussions of failure. It specifies what you will do (a partial refund or discount) if your service is not as reliable as it claims to be.
Every service provider needs an SLA when a financial penalty is involved. Devising an SLA requires a good understanding of business and legal terms in order to decide appropriate penalties and consequences for an agreement breach.
So SLAs are typically set by legal and finance teams, not SRE teams.
Since SLO is an internal objective, it is more stringent than the SLA. For example, an SLA of 99.9% over a month could require an internal SLO of 99.95%. By using a tighter internal SLO in lieu of an SLA to measure reliability, companies get a chance to react and take proactive measures to avoid breaking the agreement.
SLI (Service Level Indicator)
SLI is a metric that defines the health of a service over time and is used to determine whether the SLOs are met. Selecting the right SLI is about understanding what the user expects from the service. You don’t want to use every metric you can track in the monitoring system. In fact, choosing too many SLIs can make it difficult to pay attention to the right metrics.
SLI reflects a snapshot of the current service reliability. If the SLI drops below a certain point, the service provider needs to take appropriate action in order to increase availability.
SLI is generally the ratio of two numbers: Total Good Events, and Total Events.
SLI = (Total Good Events/Total Events) x100
For example:
- Number of successful HTTP requests / total HTTP Requests.
- Number of HTTP Requests that Completed Successfully in 200 ms / Total HTTP Requests
An SRE tries to solve the reliability issue in three ways:
- They start by defining Availability
- Finding the appropriate level of Availability that the service needs
- Creating a plan to deal with Failure of Availability
The three metrics must be communicated across every level of the organization. That includes everyone from developers to SREs and VPs. Only by having a shared goal can you make the product better than ever.
Now, let’s take a look at how the three acronyms (SLO, SLA, and SLI) work together and in conjunction with the error budget.
Suppose a payment service has an SLA of 98%, then the SLO must be higher. Considering an SLO of 99% availability, the error budget would be 1%. That 1% in a one-year window is 3.65 days of downtime. Now, after 15 days, if the SLI is 99.5%, then you’re meeting your SLO and within your EB. If the SLI dips below 99%, then you’ve used up all of your EB and are no longer meeting the SLO.
How is an Error Budget Determined and by Whom?
The error budget sets the appropriate level of reliability that the service’s customers should expect. Within the budget, the users are likely to be happy (as long as they’re satisfied with the service). If you burn all your error budget, customers are likely to start complaining and be unhappy with the service.
The number of nines reflects the availability of the service. When someone mentions four nines (99.99%) of availability, then it means that it is acceptable for the service to be down for only 52 minutes and 35 seconds a year, which is the EB for the year.
A common misconception is that the EB allocated will be consumed in one contiguous chunk with a single incident, causing executives’ concerns about customers' experience. While this scenario may happen, more frequently, EBs are consumed in small portions throughout the month or year.
More decimals mean higher uptime and a smaller EB. For example, if you define a rule in your SLO specifying that the system will respond in under 600ms 99 times out of 100, and the latency is over 600ms, then the system is considered to be down.
In the following availability SLO table, we will list the availability vs. downtime per year and month:
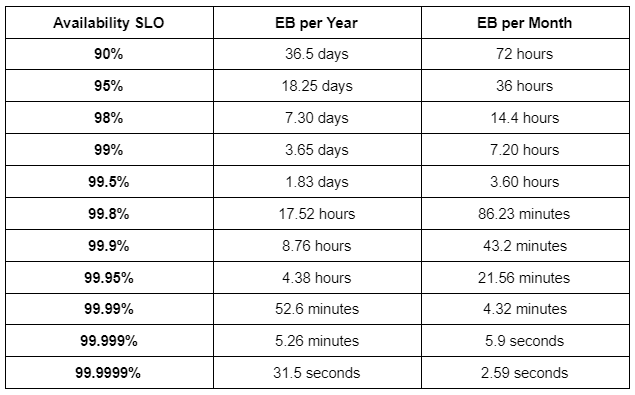
Now, an error budget is a tool used by the SREs to balance the reliability of service with the pace of innovation. Innovation means change and the main reason behind instability is change. The development toil for new features is always competing with the development toil required for stability.
Change is inevitable and therefore the error budget works as a control mechanism to divert attention to stability as needed.
According to Google’s SRE book’s Appendix:
Error Budget = 1 - Availability SLO
For example, if the SLO is 99.9%, then to calculate error budget:
Error Budget = 1- 99.9% = 0.1%
Therefore, if your service receives 100,000 requests in four weeks, then with a 99.9% availability SLO, the error budget stands at 1000 errors in four weeks.
Making an error budget and SLO is not just an engineering decision. It’s rather a business decision that requires input from various stakeholders from all parts of the organization.
The key stakeholders involved in creating the error budget are:
- Product owners including product managers, business analysts, and product leads who try to represent the customer to the development team. They anticipate the customer needs, articulate the user journey, and communicate them to the engineering teams.
- The SRE & operations team includes DevOps, ITSM & problem, management, and infrastructure engineers. Their role is to use software to manage a service, solve problems, and automate operations tasks.
- Engineers are part of the main development team that works on the product.
- Customers are both internal and external users and stakeholders and the SLOs are non-legally binding promises that the service provider makes to them.

Source: Blameless
The error budget is usually tracked by the SRE team. However, the SRE team doesn’t make decisions regarding how it should be spent. They work with development teams to build policies for accelerating development or implementing freezes based on the remaining EB.
How to Determine Uptime and Downtime in SRE?
Your service’s uptime is one of the most important metrics that can be used to measure its performance. It shows the time or percentage of when the service is up and running.
The opposite of uptime is downtime, which is the time or percentage of when the service was down. To calculate uptime, first, we need to calculate downtime.
Here’s how you calculate downtime:
Downtime = (Total Time the Website was Down/Total Time the Website was Monitored) x100
To calculate uptime:
Uptime = 100% - Downtime Percentage
Note that uptime and downtime specifically refer to the availability SLIs and EBs. Other SLI types include latency, data freshness, throughput and would not be referred to as uptime or downtime.
How can Developers “Spend” their Error Budget?
An error budget is just like your house budget. It’s the allowed expenses (unreliability) that your system can afford without making the customer unhappy. Just like your house budget, you’re allowed to spend your EB within a given period as long as you don’t overspend.
Developers can spend the EB any way they see fit. Teams new to SLOs often release new features as frequently as they want only to suddenly realize they’ve spent all of their EB and it’s time to stop shipping new features. With better alerting, teams learn to slow down development by the time they spend a significant percentage of EB. As teams advance in SRE maturity and gain better control over how to spend their EB, they begin to strategically spend their EB by taking calculated risks with shipping innovative or experimental features. EB prevents companies from going after too much reliability at the expense of these innovation opportunities that don’t impact customer happiness.
This is how EB can eventually speed up innovation and velocity. In fact, increasing the development velocity will give your product an advantage over the others. By outpacing your competitor, you’re urging companies to buy your product first. Since you’re the first one in the market, there’s less competition and more chances of success. By the time your competitor’s product even hits the market, you’re already hitting your business goals!
What Actions Should a Team Take if their Error Budget is Spent or Close to Spent?
The SRE team works with the development team to implement alerts and policies to minimize customer impact in the case when different amounts of error budget have been burned (50%, 75%, 100%, for example). A team may choose to alert higher levels of management as the EB burndown gets closer to 100% and the manager would determine the best course of action accordingly. This alerting/EB policy is what makes EBs and SLOs actionable. In fact, Twitter did not successfully implement SLOs until they instituted EB policies as well.
If a team has burned their entire error budget, previously agreed-upon policies can come into effect to prevent further customer impact. For example, the manager may go into code red and freeze all new releases until they’ve brought the number of errors down to a reasonable point. If there are way too many errors, then the SRE team may have to do a system rollback. That gives developers enough time to deal with the errors gradually and release the changes over time.
Here are some ways that the development team can focus on improving reliability instead of shipping new features when the error budget is spent or nearly spent:
- Fixing bugs in the program code or resolving procedural errors.
- Soften hard dependencies that were identified in previous incident retrospectives. Removing dependencies will make the code less complex and easier to manage.
- If the EB was consumed by miscategorized errors (incorrectly categorized errors) that would have caused the service to miss its SLO, the errors must be categorized appropriately to avoid further confusion.
What Actions can the Development Team take if they are well Above the Target Uptime?
If the development team is well above the target uptime, then they have an advantage. It allows them to increase their push velocity and take risks without putting the product at risk.
Here are a few things that the development team can do if they’re well above the target uptime:
- Introduce bigger changes
- Increase release velocity
- Take risks without troubling the SRE team
Error Budget and Maintenance Window
Every system requires some level of maintenance from time to time. In SRE, the maintenance window is a pre-allotted time frame designated by the technical staff. It's dedicated to preventive maintenance that requires disrupting the system’s normal operation.
Technologies like virtualization, multi-threaded processors, and containerization have reduced or eliminated the need for a maintenance window.
Everyone tries to minimize downtime, but sometimes it’s simply unavoidable.
In such a case, should the maintenance window affect the error budget?
You can treat maintenance as downtime by burning through the error budget associated with service availability. However, it’s not exactly a good practice, and the decision should be made only if you’re considering the downtime as part of your reliability work, and plan to reduce that. Ideally, there’s an option to exempt maintenance window errors from being counted towards the EB.
Let’s take a look at two scenarios where the maintenance window is mandatory, and how to choose a suitable maintenance window.
Business Hours
When we’re dealing with a service where operations run from 9 to 5, then the service can be down outside of the business hours. That gives the service provider the maintenance window of about ~15 hours, where they can keep the service down without affecting their EB.
Traffic Analysis
Scheduling the maintenance window by analyzing traffic patterns and choosing a time where the traffic is low. In this scenario, you're still receiving requests but are minimizing the impact on customers.
How can Blameless Help You Track and Implement Error Budgets?
Creating an error budget is a long journey, but the benefits are worth the investment. Working with SRE and creating an EB should be an indispensable part of your journey towards developing more reliable software.
Blameless provides the industry’s first end-to-end SRE platform that empowers you to optimize your service for reliability without sacrificing innovation. Our SLO product enables customers to create user journeys and SLOs, set EB policy and notifications, and automatically kick off an incident when EB is depleted. Sign up for a free trial today.